
- Today
- Total
hye-log
[부스트캠프 AI Tech]WEEK 05_DAY 23 본문
🥔 개별학습
[9] Multi-modal
1. Overview of multi-modal learning
1) Multi-modal learning : 다양한 데이터 type, 형태, 특성을 갖는 데이터로 학습하는 방법
2) challenge
- 데이터의 형태가 다양하기 때문에 표현 방식도 다름
- 서로 다른 modality에서 오는 정보의 양이 unbalance함
- 여러 modality를 사용할 때 biased됨
3) maching, translating, referencing 등 다양한 방법으로 multi-modal learning 사용
2. Multi-modal tasks(1) - Visual data & Text
1) Text embedding
- character는 ML에서 사용하기 어려움 -> dense vector로 표현
- 일반화 능력이 있음
예) man - woman -> king - queen
- skip-gram model : 단어 사이의 관계성을 통해 주변 N개의 단어를 예측
2) Joint embedding
(1) Image tagging
- 주어진 image에서 tag를 생성하거나 tag를 이용해서 image 생성
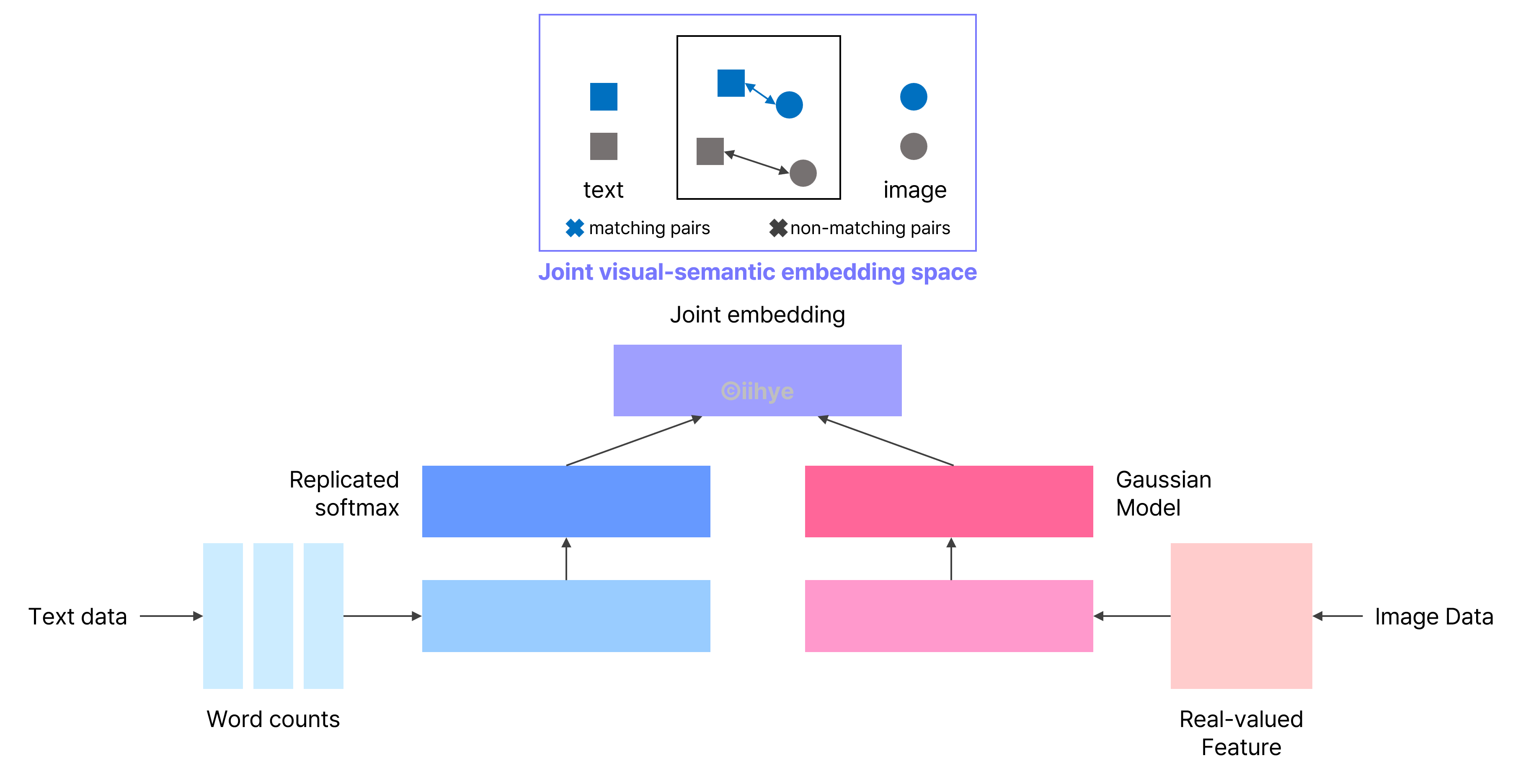
- image와 text를 같은 dimension으로 표현해서 비슷하면 embedding vector 크기가 작고, 다르면 embedding vector 크기가 크게 표현
- 같은 embedding space에 매칭시켰을 때 text와 image가 pair면 distance를 줄이고, pair가 아니면 distance가 크도록 metric learning 진행
(2) Image&food recipe retrieval
- recipt를 RNN을 통해서 fixed vector를 뽑아냄
- cosine similarity loss를 이용하여 recipt과 image가 연관이 높으면 loss를 크게, 연관이 낮으면 loss를 낮게 함
- semantic regularization loss를 이용하여 high-level semantics를 통합
3) Corss modal translation
(1) Image captioning
- image는 CNN을 통해서 학습하고, sentence는 RNN을 통해서 학습함
(2) Show and tell
- Encoder는 ImageNet 기반의 pre-trained CNN model을 사용
- Decoder는 LSTM module 사용
(3) Show, attend and tell
- 사람의 시선이 움직이는 것(attention)처럼 특징적인 부분부터 보는 것이 특징
- image를 CNN을 통해서 얻은 heatmap과 RNN에서 나온 attention grid를 합친 vector를 출력함
(4) Visual quetion answering
- Image stream에서 영상의 feature를 추출하고, Question stream에서 text sequence를 RNN으로 encoding
3. Multi-modal tasks(2) - Visual data & Audio
1) Sound representation
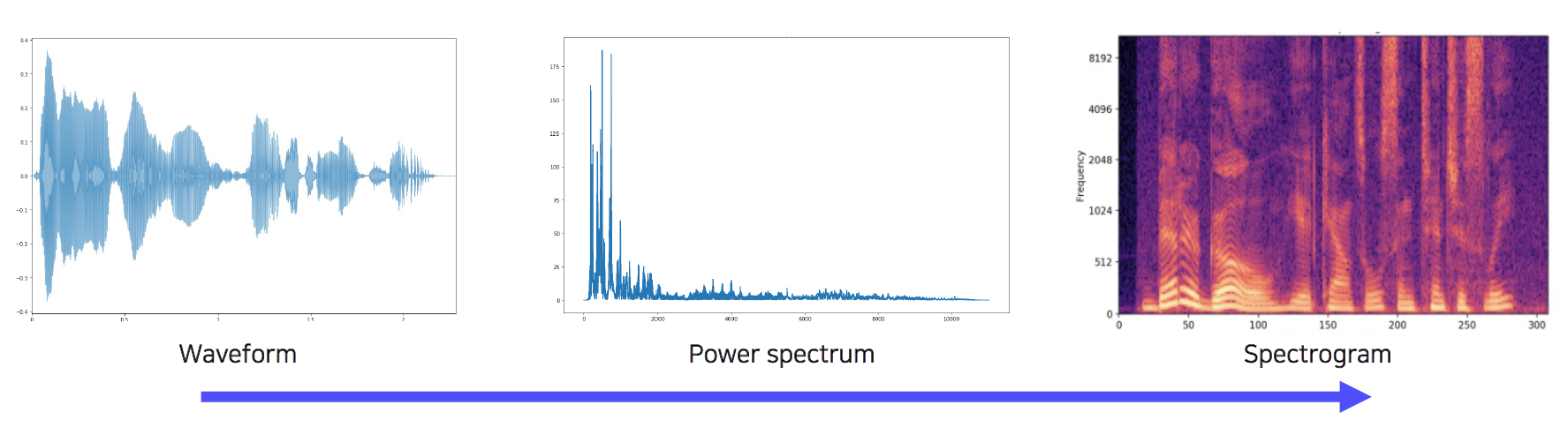
- Waveform -> Power spectrum -> Spectogram
- Fourier transform : waveform을 power spectrum으로 변환 -> 시간 축 기준을 주파수 축 기준으로 바꾸어서 삼각함수가 얼마나 들어있는지 파악
- spectogram : 시간에 따라 주파수 성분이 어떻게 변하는지 파악 가능
2) Joint embedding
(1) Scene recognition by sound
- SountNet :비디오의 RGB frames로부터 audio reprentation을 학습함
3) Cross modal translation
(1) Speech2Face
- 음성을 듣고 얼굴을 상상하는 모델
(2) Image-to-speech synthesis
- image를 보고 speech를 만들어 냄
- Image를 CNN 모델에 넣고 unit을 출력하고, unit을 TTS(Text-to-Speech)에 넣어 speech를 출력함
4) Cross modal reasoning
(1) Sound source localization
- image에서 소리가 어디에서 나는지 찾기
- image와 audio를 CNN에 넣고 spatial feature를 유지하여 localization score를 출력함
🥔 오늘의 회고
오늘은 멘토링을 시작! 멘토링 때에는 진로 관련된 고민 하나를 해결(?)해주시고, 한 가지 논문을 리뷰해주셨다. 어떻게 선택하게 되었는지, 논문에서 어떤 부분을 주의 깊게 봐야하는지, 어떻게 논문을 자신의 분야에 적용할 수 있는지까지 알려주셔서 논문 리뷰에서 어디에 주목해서 봐야하는지를 알 수 있었다. 오후에는 강의 하나를 듣는데, multi-modal이 들어보기만 했지 이론적으로 공부하는건 처음이라 어렵기도 했지만 생각보다 다양한 데이터를 가지고 학습을 시키고 정보를 얻는다는 것이 새로웠다. 스페셜 피어세션 때에는 각자 팀 현재 어떻게 구성하고, 어떤 주제로 할지를 고민했는데, 사실 우리는 이제 막 CV를 시작한 단계일 뿐인데 팀 정하는 것은 너무 어렵다는 이야기를 공통적으로 했다... 피어세션 때에는 한 주를 마무리 하는 회고를 작성하고, 다음주부터 시작되는 경진대회 관련해서 어떻게 깃을 운영할지를 이야기했다. 사실 아직 아무것도 아는 게 없어서 어떤 것이 정답일지 모르겠지만 다들 처음하는 프로젝트인만큼 많이 부딪혀보고 배워보는 것에 공감했다. 이번 한 주도 무사히 지나갔고, 다음 주 대회도 열심히 해보자!!!!
'Boostcourse > AI Tech 4기' 카테고리의 다른 글
| [부스트캠프 AI Tech]WEEK 06_DAY 25 (0) | 2022.10.25 |
|---|---|
| [부스트캠프 AI Tech]WEEK 06_DAY 24 (0) | 2022.10.25 |
| [부스트캠프 AI Tech]WEEK 05_DAY 22 (1) | 2022.10.20 |
| [부스트캠프 AI Tech]WEEK 05_DAY 21 (0) | 2022.10.20 |
| [부스트캠프 AI Tech]WEEK 05_DAY 20 (0) | 2022.10.20 |



