
- Today
- Total
hye-log
[부스트캠프 AI Tech]WEEK 10_DAY 45 본문
⚽ 개별학습
[7] Advanced Object Detection 1
3. Transformer
1) Overview
(1) Transformer
- NLP에서 long range dependency 해결 -> Vision에서 Vision Transformer(ViT)로 발전
- End-to-End Object Detection with Transformers(DETR)
- Swin Transformer
(2) Self Attention
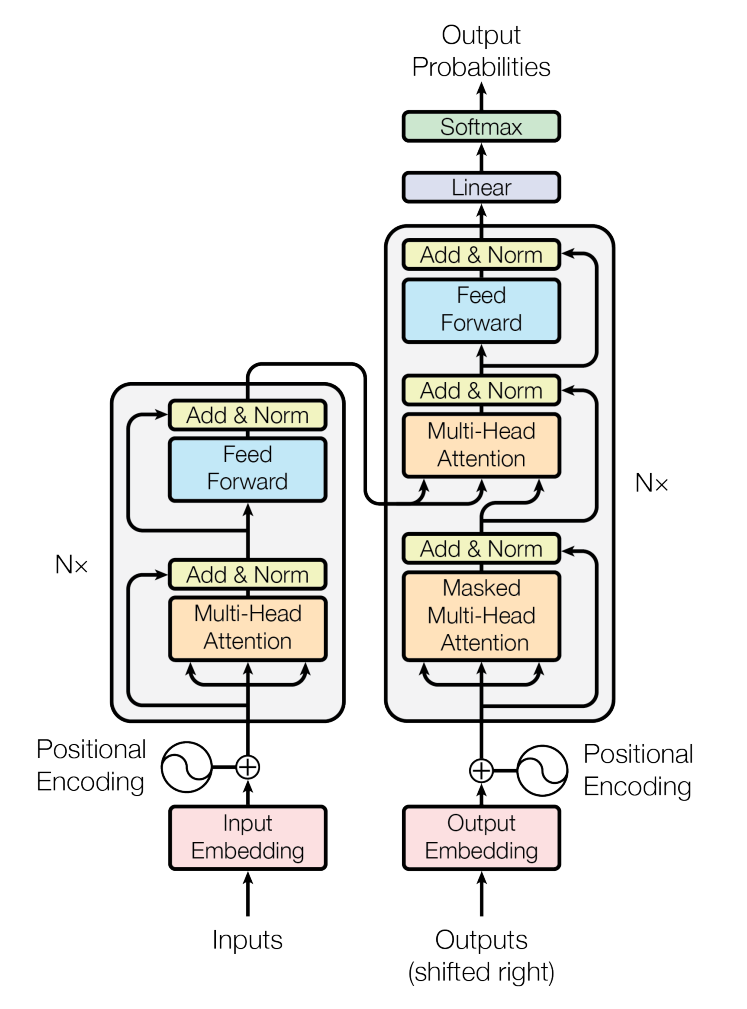
- Input(text)를 deep learning이 이해할 수 있는 포맷인 vector로 변환해줌
- Input embedding과 Positional Encoding을 합쳐서 network에 넣어줌
2) Vision Transformer(ViT)
(1) Overview
- Flatten 3D to 2D (Patch 단위로 나누기)
- Learnable한 embedding 처리
- class embedding, position embedding 합치기
- Transformer
- Predict
(2) ViT의 문제점
- 많은 양의 Data를 학습해야 함
- computational cost가 큼
- 일반적인 backbone으로 사용하기 어려움
3) End-to-End Object Detection with Transformer
(1) Contribution
- transformer를 처음으로 object detection에 적용
- 기존 object detection의 hand-crafted post process 단계에서 transformer를 이용함
(2) Architecture
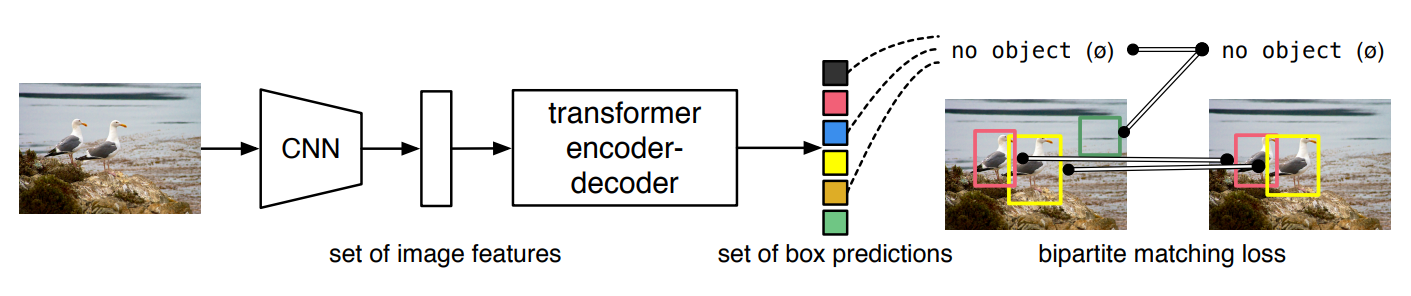
- 1 stage -> CNN backbone -> transformer encoder-decoder -> prediction head
- highest level feature map 사용
- Flatten 2D
- positional embedding
- Encoder-Decoder
(3) Train
- ground truth와 prediction이 N:N 매핑
- ground truth에서 부족한 object 개수만큼 no object로 padding 처리
4) Swin Transformer
(1) ViT의 문제점 해결
- CNN과 유사한 구조로 설계
- window로 cost를 줄임
(2) Architecture
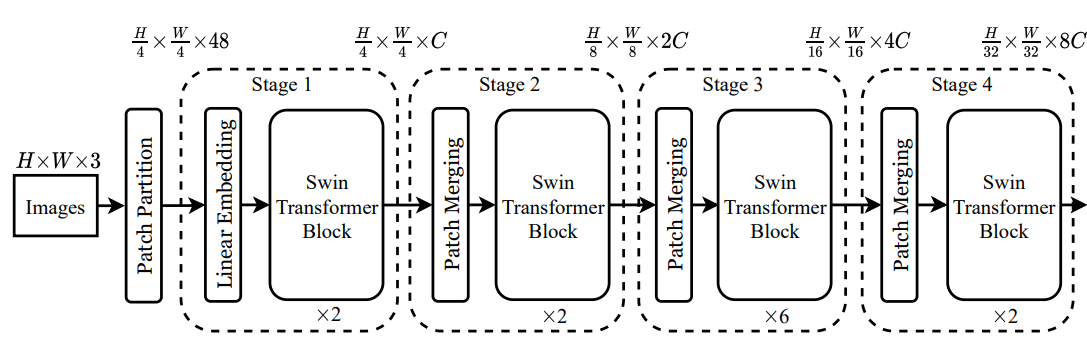
- transformer를 4개로 나누어서 각 stage 별로 transformer를 수행함
- Patch partitioning : image를 patch로 나누어줌
- Linear embedding : Patch에 embedding 더하기 (class embedding을 제거)
- Swin transformer block : attention을 두 번을 진행함. cost를 줄임.
- Window Multi-head Attention : Swin tranformer에서는 Multi-head Attention 대신 Window Multi-head Attention을 사용
- Patch Merging : feature map의 사이즈를 절반으로 줄임
(3) Window Multi-head Attention
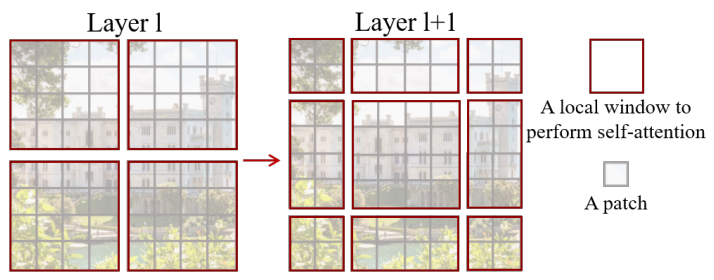
- Window 단위로 embedding을 나누고, window 안에서만 transformer 연산 수행
- 단점 : receptive field 제한
(4) Shifted Window Multi-head Attention
- transformer block 2번째 layer에서 수행
- window size와 다르게 나뉜 부분 해결 필요
(5) Summary
- 적은 data에도 학습이 잘 이루어짐
- window 단위를 사용하여 computation cost를 줄임
- CNN과 비슷한 구조로 object detection, segmentation 등의 backbone으로 활용
⚽ 오늘의 회고
오전에는 5 fold로 나눈 데이터셋 실험 결과 공유하면서 어떤 데이터셋을 선택하면 좋을지 고민했다. 결과가 4개만 나와서 validation과 test mAP 차이가 적은 데이터셋을 선택하기로 했는데, 사실 5 fold의 데이터 분포가 비슷해서 mAP도 비슷하게 나왔다. 흠.. 이러면 데이터셋을 찾는 게 의미가 있는건지 고민..! submission 파일을 보니 class, x, y 좌표를 통해서 test 이미지에 시각화 할 수 있을 거 같아서 이것저것 해보았다. 사실 엄청 잘 되지는 않고.. 자꾸 오류나고 시간도 오래 걸리고 이게 맞는지, 이게 필요한건지 잘 모르겠지만 그래도 해보는 것에 의의를 두는걸로..!
'Boostcourse > AI Tech 4기' 카테고리의 다른 글
| [부스트캠프 AI Tech]WEEK 10_DAY 47 (0) | 2022.11.24 |
|---|---|
| [부스트캠프 AI Tech]WEEK 10_DAY 46 (0) | 2022.11.23 |
| [부스트캠프 AI Tech]WEEK 10_DAY 44 (0) | 2022.11.22 |
| [부스트캠프 AI Tech]WEEK 09_DAY 43 (0) | 2022.11.18 |
| [부스트캠프 AI Tech]WEEK 09_DAY 42 (1) | 2022.11.18 |



