
- Today
- Total
hye-log
[부스트캠프 AI Tech]WEEK 01_DAY 03 본문
🌟 개별학습
[2] 행렬이 뭐에요
1. 행렬
1) 벡터를 원소로 가지는 2차원 배열
x = np.array([[1, -2, 3], # 하나의 행을 나타냄
[7, 5, 0],
[-2, -1, 2]])2) 행(row)과 열(column) 인덱스를 가짐

3) 전치 행렬(transpose matrix) : 행과 열의 인덱스가 바뀐 행렬
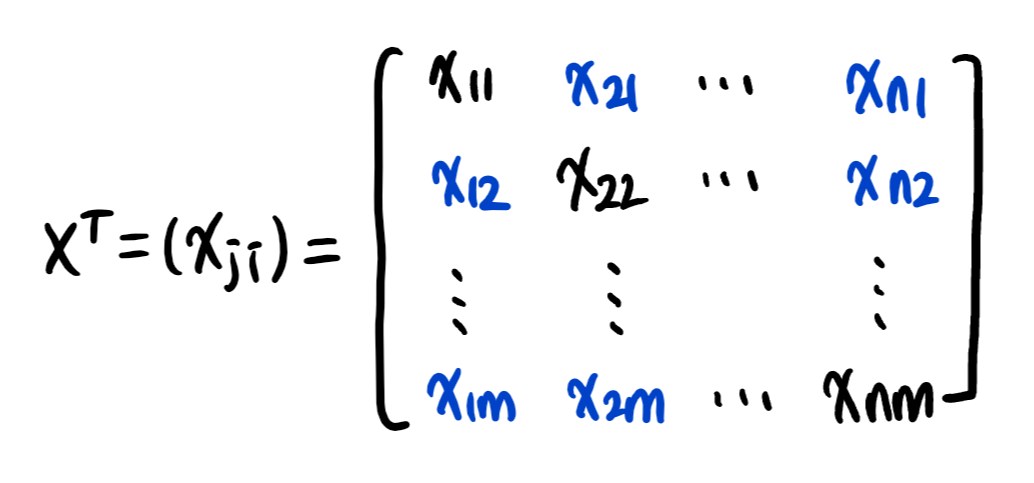
2. 행렬을 이해하는 방법 (1)
1) 행렬 - 여러 점들을 나타냄 (vs. 벡터 - 공간에서의 한 점)
2) xij : i번째 데이터의 j번째 변수의 값
3. 행렬의 연산
1) 행렬의 덧셈, 뺄셈 : 행렬끼리 같은 모양을 가지면 계산 가능
2) 행렬의 성분곱, 스칼라곱 : 벡터와 동일
3) 행렬의 곱셈 : i번째 행벡터와 j번째 열벡터 사이의 내적
+ X행의 개수와 Y의 열의 개수가 같아야 함
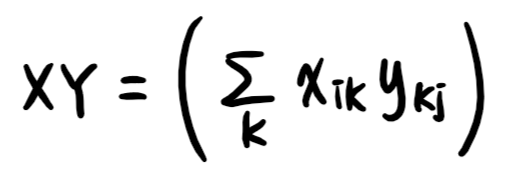
# 행렬의 곱셈
X = np.array([[1, -2, 3], [7, 5, 0], [-2, -1, 2]])
Y = np.array([[0, 1], [1, -1], [-2, 1]])
X @ Y
>> array([[-8, 6], [5, 2], [-5, 1]])4) 행렬의 내적 : i번째 행벡터와 j번째 행벡터 사이의 내적을 성분으로 가지는 행렬
+ X의 행의 개수와 Y의 행의 개수가 같아야 함

# 행렬의 내적
X = np.array([[1, -2, 3], [7, 5, 0], [-2, -1, 2]])
Y = np.array([[0, 1, -1], [1, -1, 0]])
np.inner(X, Y)
>> array([[-5, 3], [5, 2], [-3, -1]])
4. 행렬을 이해하는 방법(2)
1) 벡터공간에서 사용되는 연산자(operator)
2) 행렬곱을 통해 벡터를 다른 차원의 공간으로 보낼 수 있음 -> 패턴 추출, 데이터 압축
5. 역행렬
1) 역행렬(inverse matrix) : 행렬 A의 연산을 거꾸로 되돌리는 행렬
+ 행과 열 숫자가 같고 행렬식이 0이 아닌 경우에만 가능
2) AA^-1 = A^-1A = I (항등행렬)
# 역행렬
X = np.array([[1, -2, 3], [7, 5, 0], [-2, -1, 2]])
np.linalg.inv(x) # 역행렬
X @ np.linalg.inv(x) # 항등행렬3) 역행렬을 계산할 수 없다면, 유사역행렬(pseudo-inverse) / 무어-펜로즈(Moore-Penrose) 역행렬 사용
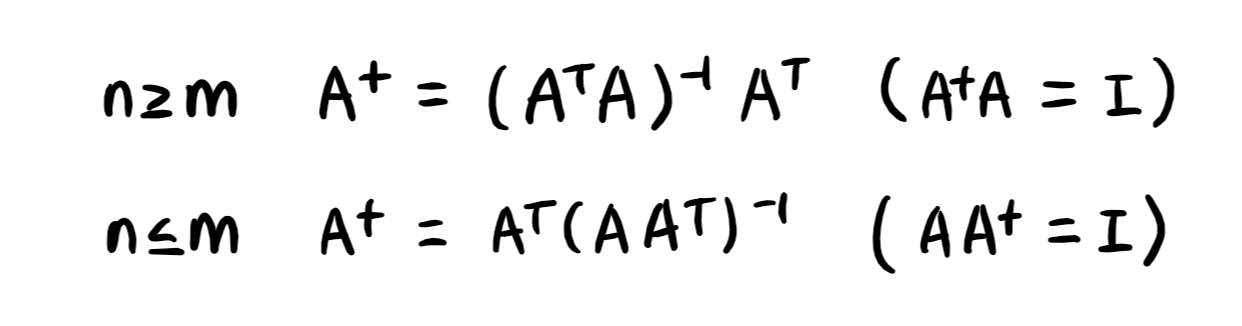
# 유사역행렬
X = np.array([[0, 1], [1, -1], [-2, 1]])
np.linalg.pinv(x) # 유사역행렬
X @ np.linalg.pinv(x) # 항등행렬[3] 경사하강법(순한맛)
1. 미분
1) 변수의 움직임에 따른 함수값의 변화를 측정하기 위한 도구
2) 최적화에서 제일 많이 사용하는 기법
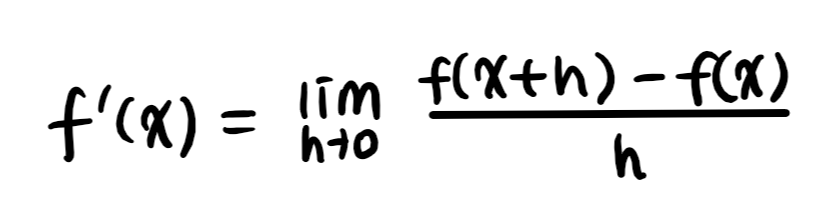
# 미분의 계산
import sympy as sym
from sympy.abc import x
sym.diff(sym.poly(x**2 + 2*x + 3), x)
>> Poly(2*x + 2, x, domain='ZZ')3) 함수 f의 주어진 점 (x, f(x))에서의 접선의 기울기를 구하는 것
4) 접선의 기울기를 알면 -> 어느 방향으로 점을 움직어야 함수값이 증가/감소하는지 알 수 있음
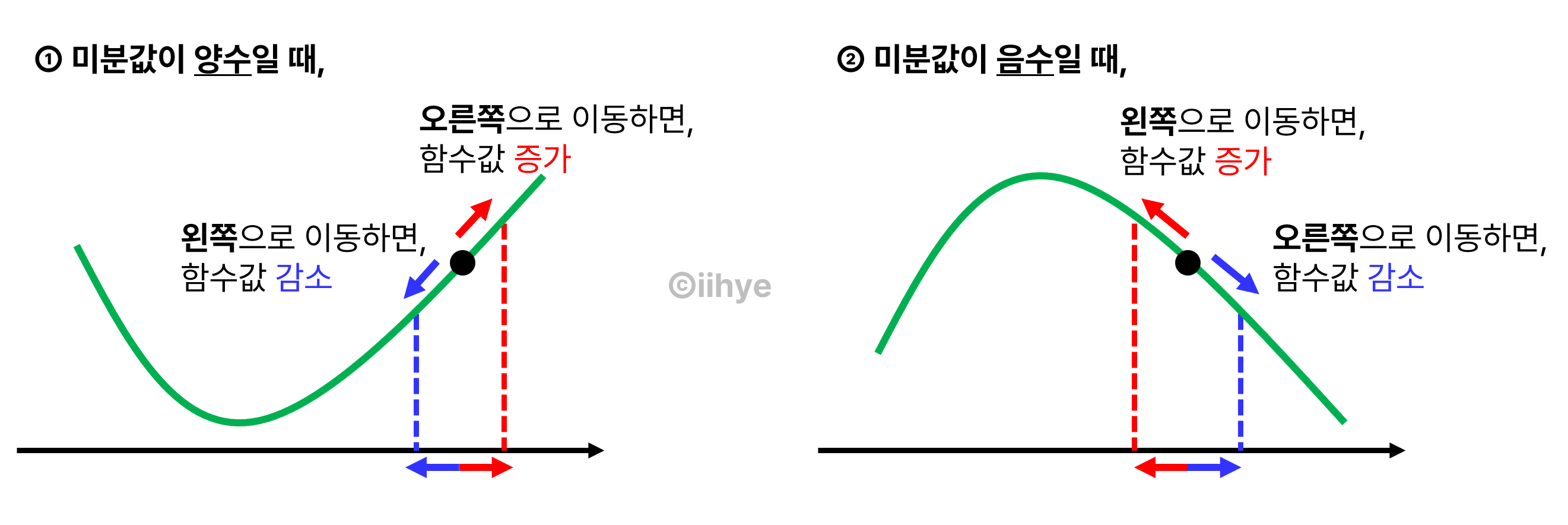
5) 경사상승법(gradient ascent) : 미분값을 더하여 함수의 극대값 위치를 구함
6) 경사하강법(gradient descent) : 미분값을 빼서 함수의 극소값 위치를 구함
7) 극값에 도달하면 움직임을 멈춘다 = 목적함수 최적화가 끝난다
8) 경사하강법의 알고리즘
- Input : gradient(미분을 계산하는 함수), init(시작점), lr(학습률), eps(알고리즘 종료조건)
- Output : var
var = init
grad = gradient(var)
while(abs(grad) > eps): # 알고리즘 종료 조건
var = var - lr * grad # 미분을 통해 업데이트 속도 조절
grad = gradient(var) # 미분값 업데이트9) 다변수 함수의 경우 편미분(partial differentiation)을 사용
10) 그레디언트 벡터 : (예) f(x, y) = x^2 + 2*y^2 => ∇f = (2x, 4y)
11) 경사하강법의 알고리즘(2)
- Input : gradient(그레디언트 벡터를 계산하는 함수), init(시작점), lr(학습률), eps(알고리즘 종료조건)
- Output : var
var = init
grad = gradient(var)
while(norm(grad) > eps): # 알고리즘 종료 조건
var = var - lr * grad # 그레디언트를 통해 업데이트 속도 조절
grad = gradient(var) # 그레디언트값 업데이트[4] 경사하강법(매운맛)
1. 선형회귀분석 복습
1) np.linalg.pinv(역행렬)를 이용하여 데이터를 선형모델로 해석하는 선형회귀식을 찾을 수 있음
2) 역행렬 대신 경사하강법을 이용한 선형모델을 찾아보자 -> L2 노름 활용
2. 경사하강법을 이용한 선형회귀
1) 선형회귀의 목적식

2) 목적식을 최소화하는 β를 구하는 경사하강법 알고리즘
+ L2 노름 대신 L2 노름의 제곱으로 구해도 됨 -> 계산이 간단해짐

3) 경사하강법 기반 선형회귀 알고리즘
- Input : X, y, lr(학습률), T(학습횟수)
- Output : beta
for t in range(T):
error = y - X @ beta
grad = -transpose(X) @ error # 그레디언트 벡터
beta = beta = lr * grad # beta 업데이트4) 경사하강법은 미분 가능하고, 볼록한(convex) 함수에 대해서 적절한 학습률과 학습횟수를 선택했을 때 수렴이 보장
5) 비선형회귀의 경우 목적식이 볼록하지 않으므로 수렴이 항상 보장되지 않음 -> 확률적 경사하강법을 사용
3. 확률적 경사하강법(SGD, Stochastic Gradient Descent)
1) 데이터 한 개 또는 일부를 활용하여 업데이트
2) 볼록이 아닌(non-convex) 목적식을 최적화할 수 있음
3) 미니배치를 확률적으로 선택하기 때문에 목적식 모양이 바뀔 수 있음
4) 이미지 데이터는 사이즈도 크고 크기도 크기 때문에 모든 데이터를 업로드하면 메모리가 부족하므로 SGD 활용
[5] 딥러닝 학습방법 이해하기
1. 신경망(neural network)
1) 비선형모델 = 선형모델 + 활성함수(activation function)
2) O = X * W + b
- 행 벡터 oi는 데이터 xi와 가중치 행렬 W 사이의 행렬곱과 절편 b 벡터의 합으로 표현
- O(n x p) = X(n x d) * W(d x p) + b(n x p)
3) 다층(multi-layer) 퍼셉트론(MLP) : 신경망 여러층이 합성된 함수
4) 층이 깊을수록 -> 목적함수를 근사하는데 필요한 뉴런의 숫자가 훨씬 빨리 줄어들어 -> 효율적 학습 가능
+ 층이 깊다고 -> 최적화가 쉬운 것은 아님
2. 소프트맥스(Softmax)
1) 모델의 출력을 확률로 해석할 수 있게 변환해주는 연산
2) softmax(o) = softmax(Wx+b)
def softmax(vec):
denumerator = np.exp(vec - np.max(vec, axis=-1, keepdims=True))
numerator = np.sum(denumerator, axis=-1, keepdims=True)
val = denumerator / numerator
return val3) 분류 문제를 풀 때 선형모델과 소프트맥스 함수를 결합하여 예측
4) 추론을 할 때는 원-핫(one-hot) 벡터로 최대값을 가진 주소만 1로 출력하는 연산을 사용
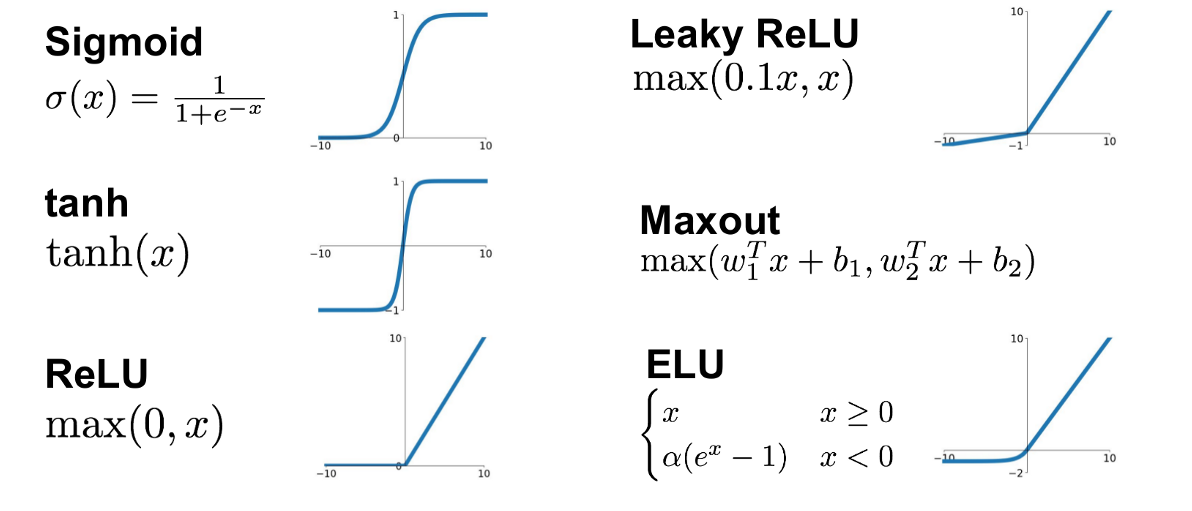
3. 활성함수(activation function)
1) 딥러닝에서 선형모델과 차이를 추기 위해서 활성함수를 사용
2) sigmoid, tanh -> 전통적으로 많이 쓰이던 활성함수 / ReLU -> 딥러닝에서 자주 사용
4. 역전파 알고리즘(backpropagation)
1) 딥러닝의 학습원리
2) forwardpropagation : 입력 -> 선형모델 -> 활성화함수 -> 출력 형태
3) backpropagation : 경사하강법 적용하여 gradient vector를 계산
4) 연쇄법칙(chain-rule) 기반 자동 미분(auto-differentiation)
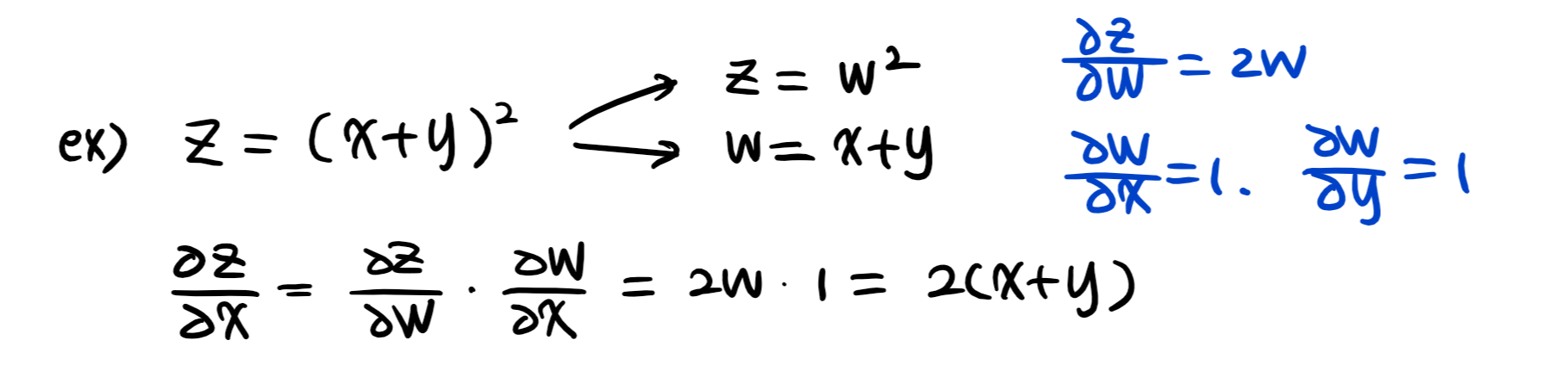
[6] 확률론 맛보기
1. 딥러닝과 확률론
1) 딥러닝은 확률론 기반의 기계학습 이론에 바탕을 둠
2) 손실함수(loss function)의 작동 원리 : 데이터 공간을 통계적으로 해석해서 유도함
(예) 회귀 분석의 손실 함수로 사용되는 L2-노름 : 예측오차의 분산을 가장 최소화하는 방향으로 학습
(예) 분류 문제의 교차 엔트로피(cross-entropy) : 모델 예측의 불확실성을 최소화하는 방향으로 학습
2. 확률분포
1) 데이터공간 : X × Y, 데이터공간에서 데이터를 추출하는 분포 : D
+ 정답 레이블이 있는 지도학습이라고 가정
2) 데이터 : 확률변수 (x, y) ~ 확률분포 D ( (x, y) ∈ X × Y )
3) 확률변수 : 확률분포 D 에 따라 구분
- 이산확률변수(discrete) : 확률변수가 가질 수 있는 경우의 수를 모두 고려하여 확률을 더해서 모델링
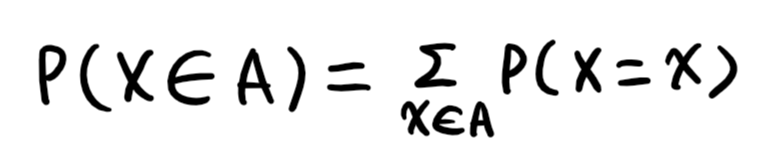
- 연속확률변수(continuous) : 데이터 공간에 정의된 확률변수의 밀도 위에서 적분을 통해 모델링
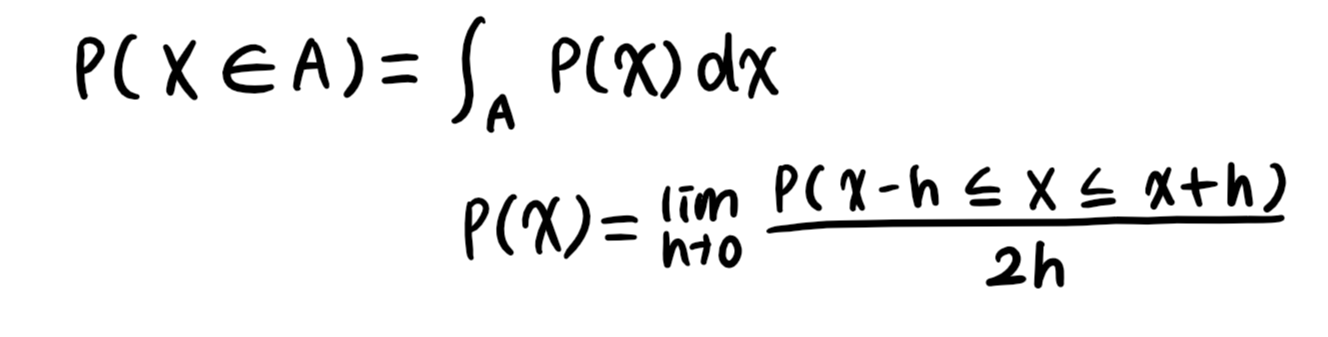
4) 결합분포 P(x, y)는 D를 모델링
5) P(x) : 입력 x 에 대한 주변확률분포. y에 대한 정보는 없음
6) P(x | y) : 조건부확률분포. 데이터공간에서 입력 x와 출력 y 사이의 관계를 모델링
3. 조건부확률
1) P(y | x) : 입력변수 x에 대해 정답이 y일 확률
(예) 로지스틱 회귀에서 사용한 선형모델 + 소프트맥스는 데이터에서 추출된 패턴을 기반으로 확률을 해석하는데 사용
(예) softmax(WΦ + b)는 데이터 x로부터 추출된 특징패턴 Φ(x)과 가중치행렬 W를 통해 조건부확률 P(y|x)를 계산
(예) 회귀 문제에서는 조건부기대값 E[y | x]를 추정함
4. 기대값(expectation)
1) 데이터를 대표하는 통계량
2) 이산확률분포의 기대값 : 급수를 사용
+ 이산확률분포의 기대값을 E[x]라 할 때, 분산은 V[x]=E[x^2]-E[x]^2
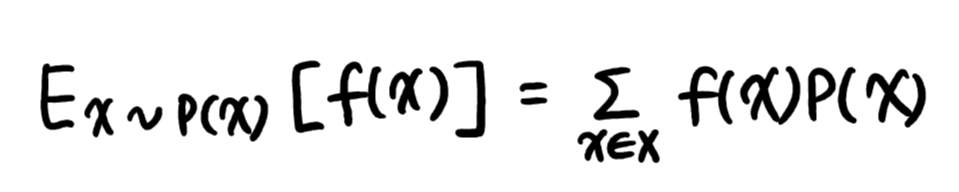
3) 연속확률분포의 기대값 : 적분을 사용
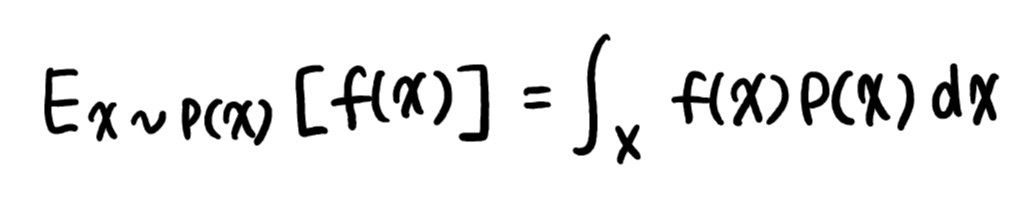
4) 딥러닝은 다층신경망을 사용하여 데이터로부터 특징패턴을 추출함
5. 몬테카를로 샘플링(Monte Carlo)
1) 확률분포를 모를 때 데이터를 이용하여 기대값을 계산하려면 몬테카를로 샘플링 방법을 사용
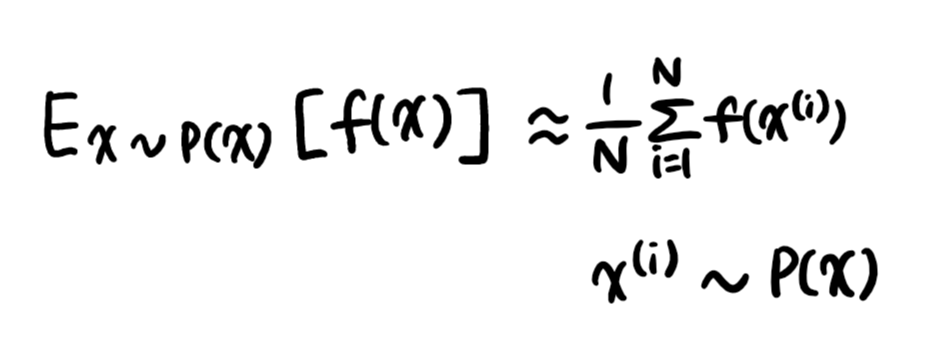
2) 독립추출만 보장된다면 대수의 법칙에 의해 수렴성 보장
[7] 통계론 맛보기
1. 모수
1) 통계적 모델링은 적절한 가정 위에서 확률분포를 추정하는 것이 목표
2) 유한한 개수의 데이터만 관찰해서 모집단의 분포를 알기 어려움 -> 근사적으로 확률분포를 추정
3) 모수적(parametric) 방법론 : 데이터가 특정 확률분포를 따른다고 선험적으로 가정한 후 그 분포를 결정하는 모수를 추정하는 방법
4) 비모수(nonparametric) 방법론 : 특정 확률분포를 가정하지 않고 데이터에 따라 모델의 구조 및 모수의 개수가 유연하게 바뀌는 방법 -> 기계학습의 많은 방법론
(예) 확률분포 가정하기 -> 우선 히스토그램을 통해 모양을 관찰
- 데이터가 2개의 값(0 또는 1)만 가짐 -> 베르누이 분포
- 데이터가 n개의 이산적인 값을 가짐 -> 카테고리 분포
- 데이터가 [0, 1] 사이에서 값을 가짐 -> 베타 분포
- 데이터가 0 이상의 값을 가짐 -> 감마 분포, 로그정규 분포
- 데이터가 R 전체에서 값을 가짐 -> 정규 분포, 라플라스 분포 등
5) 데이터를 생성하는 원리를 먼저 고려할 것
2. 모수 추정
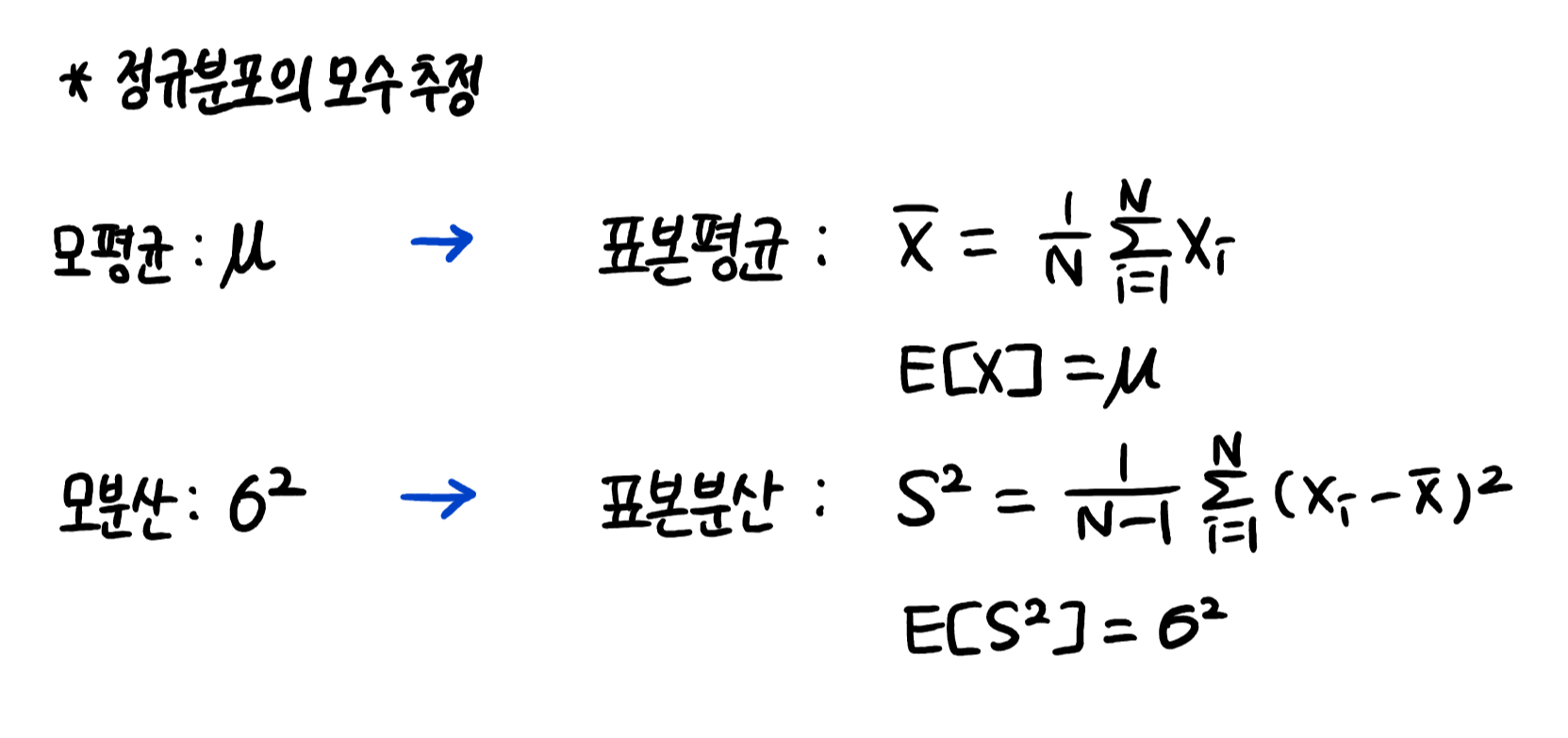
1) 표집분포(sampling distribution) : 통계량의 확률분포
2) 중심극한정리(Central Limit Theorem) : N이 커질수록 정규분포 N(μ, σ^2/N)을 따름
3. 최대가능도 추정법(MLE, Maximum Likelihood Estimation)
1) 가장 가능성이 높은 모수를 추정하는 방법 중 하나
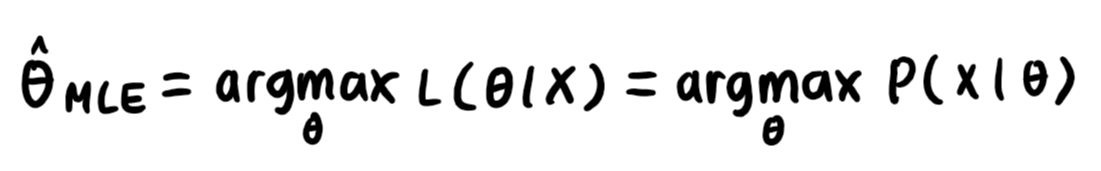
2) 가능도(likelihood) : 모수 θ를 따르는 분포 x를 관찰할 가능성
+ 확률로 해석 X. 대소 비교가 가능한 함수 정도로 해석 O
3) 데이터 집합 X가 독립적으로 추출되었을 경우 로그가능도를 최적화함
+ 로그가능도를 사용하는 이유 : 연산량을 줄여줌
4) 딥러닝에서 최대가능도 추정법 : 원핫벡터로 표현한 정답레이블을 이용해 확률변수인 소프트맥스 벡터의 로그가능도를 최적화

4. 확률분포의 거리
1) 손실함수는 모델이 학습하는 확률분포 ~ 데이터에서 관찰되는 확률분포의 거리를 통해 유도
2) 총변동 거리(TV, Total Variation Distance)
3) 쿨백-라이블러 발산(KL, Kullback-Leibler Divergence)
- 이산확률변수

- 연속확률변수
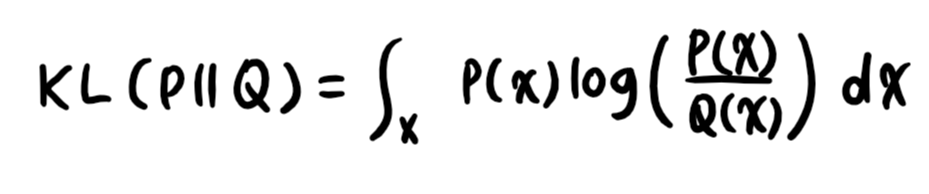
- 분해

- 정답 레이블을 P, 모델 예측을 Q라고 할 때, 최대가능도 추정법은 쿨백-라이블러 발산을 최소화함
4) 바슈타인 거리(Wasserstein Distance)
🌟 오늘의 회고
오전에 피어세션이피었습니다🌸를 시작으로 하루가 시작되었다. 같은 트랙의 다른 캠퍼분들도 궁금했는데 이번 세션을 통해서 다른 캠퍼분들은 어떤 분들인지, 어떻게 그라운드 룰을 정하고 피어세션을 운영하고 있는지 알아볼 수 있었다. CV 트랙은 팀이 많아서 반씩 나누어서 한 게 아쉬웠다ㅠ-ㅠ 세션이 끝나고 잠깐 쉬고 점심을 먹고, 다시 학습에 들어갔다. 어제부터 살짝 강의를 다 들을 수 있을지 걱정이 되어서 오늘은 완전 집중해서 강의랑 퀴즈를 풀었다🔥 여전히 확률과 통계 파트는 너무너무 어렵다ㅠㅠ 되도록이면 10시~7시 지켜서 공부하려고 했지만 오늘은 10시까지 강의 듣고 퀴즈 풀고, 심화 과제 1번도 해결해봤다! 사실 처음 심화 과제 봤을 때에는 내가 이 문제들을 풀 수 있을까 걱정만 많았는데, 막상 강의 듣고 풀고 실행을 누르니... 실행이.. 된..다...(굿) 오늘 집중한만큼 내일도 집중해서 AI Math 강의 끝내고 다시 파이썬 강의 들어가는걸로✨
'Boostcourse > AI Tech 4기' 카테고리의 다른 글
| [부스트캠프 AI Tech]WEEK 02_DAY 06 (1) | 2022.09.26 |
|---|---|
| [부스트캠프 AI Tech]WEEK 01_DAY 05 (1) | 2022.09.23 |
| [부스트캠프 AI Tech]WEEK 01_DAY 04 (1) | 2022.09.22 |
| [부스트캠프 AI Tech]WEEK 01_DAY 02 (1) | 2022.09.21 |
| [부스트캠프 AI Tech]WEEK 01_DAY 01 (1) | 2022.09.20 |



